Dist Robotics
Github

Autonomous robots through distributed reinforcement learning
In the coming years, humanoid robots will be deployed in many aspects of our lives. But the question is: who should decide what these robots can or cannot do? The simple answer: the community, through voting, just like how we vote on new laws. The means: an open-source model—for both hardware and software.
Project goal: To pave the way to an affordable open source robot that anyone can quickly assemble. This robot will be capable of sharing real world training data, guided by human feedback, with a centralized server or even better a decentralized training system. All robots of the network will benefit from updated model weights.
Through open source code development, task demonstrations from humans and the mimicking capabilities of the robots, each individual will be able to suggest and teach new tasks that the robot can learn. The community will then be able to validate and reinforce, or reject the tasks suggested by other people.
A voting mechanism could ensure that tasks can be ruled out from the system if deemed dangerous, and a reward mechanism could remunerate contributers (writing reward functions, ranking real world robot trajectories, recording videos for immitation learning, etc).
The project's name, "Dist Robotics", reflects this core idea of distributed, community-driven robotic learning. But before any of this, the robot has to be built.
Success Criteria: The robot should pick up a light object, like an apple, from point A and deliver it to point B, autonomously.
Technical challenges still need to be overcome for such a project. Deep reinforcement learning of simulated robots with subsequent transfer of the trained weights to the physical robots is nowadays regarded as the state of the art, but this requires powerful infrastructure and highly accurate modeling of the robots and its environment.
In this project, we settle for just a moderate modeling accuracy but investigate how real world reinforcement learning (fine-tuning the simulation weights) could make robots achieve reliable control without the excessive simulation overhead.
To achieve scalability in this setting, ideally multiple robots should provide feedback in parallel to generate sufficient data for updating the model weights globally, which can then be redistributed to all participating robots.
There are significant benefits of such an approach, here is a recap:
- Training across diverse environments would improve the robustness of the global model.
- New tasks can be aquired through human demonstration and mimicking algorithms.
- Community-based safety assessment to vote out dangerous tasks: only tasks that are validated by a majority of the community will be integrated in the model
So this project isn’t just about building a robot - it’s about building a system where the community decides how autonomous agents behave.
Intelligent Control System
The robot's main cognitive component is a deep neural network, that processes proprioceptive feedback from the joints (angle and angular velocity), stability (root orientation), and task-specific inputs at 30Hz to derive optimal actuators speed. This was chosen to simplify the hardware requirement and the model integration.
However, to really achieve a smooth motion, torque control will probably be chosen in the long run, with a higher frequency of probably 120Hz or more.
The output of the neural network is processed through a driver to modulate the voltage going through each DC motors from a 24V power supply. Each motor can apply a maximum 10Nm torque. The ankle and knee motors will soon be replaced with 20Nm ones.
To learn the optimal control output with respect to all possible state that the robot could encounter, a reinforcement learning (Proximal Policy Optimization - PPO) agent computes the appropriate feedback for each step of multiple simulated trajectories (or the real world ones) to train the deep neural network. With this AI-driven learning strategy, the robot should achieve precise and stable motion for complex and versatile tasks with minimal hardcoding required.
The feedback is based on a reward function: for example in the case of learning to walk, part of the reward might be the position at time t minus the position at t-1. If positive, the robot will reinforce the behavior. If negative, the robot will punish the behavior to lower the probability of reproducing such action under a somehow similar state.
Methods
The project applies proven concepts balancing performance and simplicity, to ensure fast development. The main inspirations came from the following:
| Title | Authors | Published | Link | Overview |
|---|---|---|---|---|
| Introduction to Reinforcement Learning | Richard S. Sutton, Andrew G. Barto | 1998 (2nd Edition: 2018) | Official Book Website | Fundamental concepts and algorithms in reinforcement learning, providing the theoretical basis for training robots to learn through interaction with their environment. |
| Proximal Policy Optimization (PPO) | John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov | 2017 | Read the Paper | PPO, a robust and efficient policy gradient method, commonly used for training robot control policies due to its stability and simplicity. |
| DeepMimic: Example-Guided Deep Reinforcement Learning | Xue Bin Peng, Pieter Abbeel, Sergey Levine, Michiel van de Panne | 2018 | Project Page | An approach for imitation learning that trains robots to mimic human-like motions from motion capture data, useful for humanoid robotics applications. |
| Continuous Control with Deep Reinforcement Learning | Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, et al. | 2016 (arXiv) | Read the Paper | Continuous action spaces, critical for motor control tasks. |
| Understanding Domain Randomization for Sim-to-Real Transfer | Chen, Wang, Zhang, and others | 2021 | Read the Paper | Domain randomization techniques for transferring RL policies from simulation to real-world robots by randomizing environment parameters during training. |
Deep Learning Models
Deep neural networks are used for various parts of the robot software, from controlling the motors to detecting objects in space, the main ones are the following:
| Model Type | Description | Used For |
|---|---|---|
| Critic Model (custom built) | Evaluates the expected return from a state (or state-action pair), helping assess how advantageous a particular action was. | RL (PPO) |
| Actor Model (custom built) | Outputs a probability distribution over actions given a state, from which actions are sampled. | RL (PPO) |
| Curiosity Model (custom built) | Enables model-based learning and "dreaming". | Planning |
| Inception-ResNet-v2 | Object position estimation in 3D space. | Computer Vision |
| Google MediaPipe | Pose estimation for joint orientation. | Deep Mimic |
Robots
The robots are designed to balance ressemblance of human morphology (to mimic behaviors easily) and simplicity for fast prototyping. For now, only the lower body has been built. The rest will be assembled once basic locomotion is achieved on the lower body.
| Feature | Legs (Lower Body) - Done | Lower and upper body - Design in process - ToDo | Full Body (With Fingers) - ToDo |
|---|---|---|---|
| Action Size (joints) | 8 | 18 | 38 |
| State Size | 48 | 78 | 150+ |
| Primary Function | Bipedal locomotion | Locomotion & basic upper body tasks | High level of dexterity |
| Electronics | Raspberry Pi, DC motors, encoders, gyroscope | Camera, microphone, loudspeaker | Servo motors |
| Size and weight | 70cm - 7kg | 131cm - 13.5kg | 131cm - 14kg |
Hardware
The development of the robot started with the CAD design of the lower body. The design underwent three major iterations, leading to significant improvements in stability, motor placement, and articulation. In total, plastic parts (PLA) have been printed with the Prusa and Creality 3D printers. Everything was assembled with M3, M4 and M6 bolts.
The electronics includes a 24 Volt power supply, a Raspberry Pi, jumper wires, DC motors, hall effect encoders, a gyroscope and multiplexers. Flange bearing are used at each joint to support the torque induced by the motors.
For now the robot can auto calibrate itself and do simple flexion and extensions - but the transferability of the weights learned through the simulation still faces challenges, mainly because of motor play and unpredictable motor dynamics.
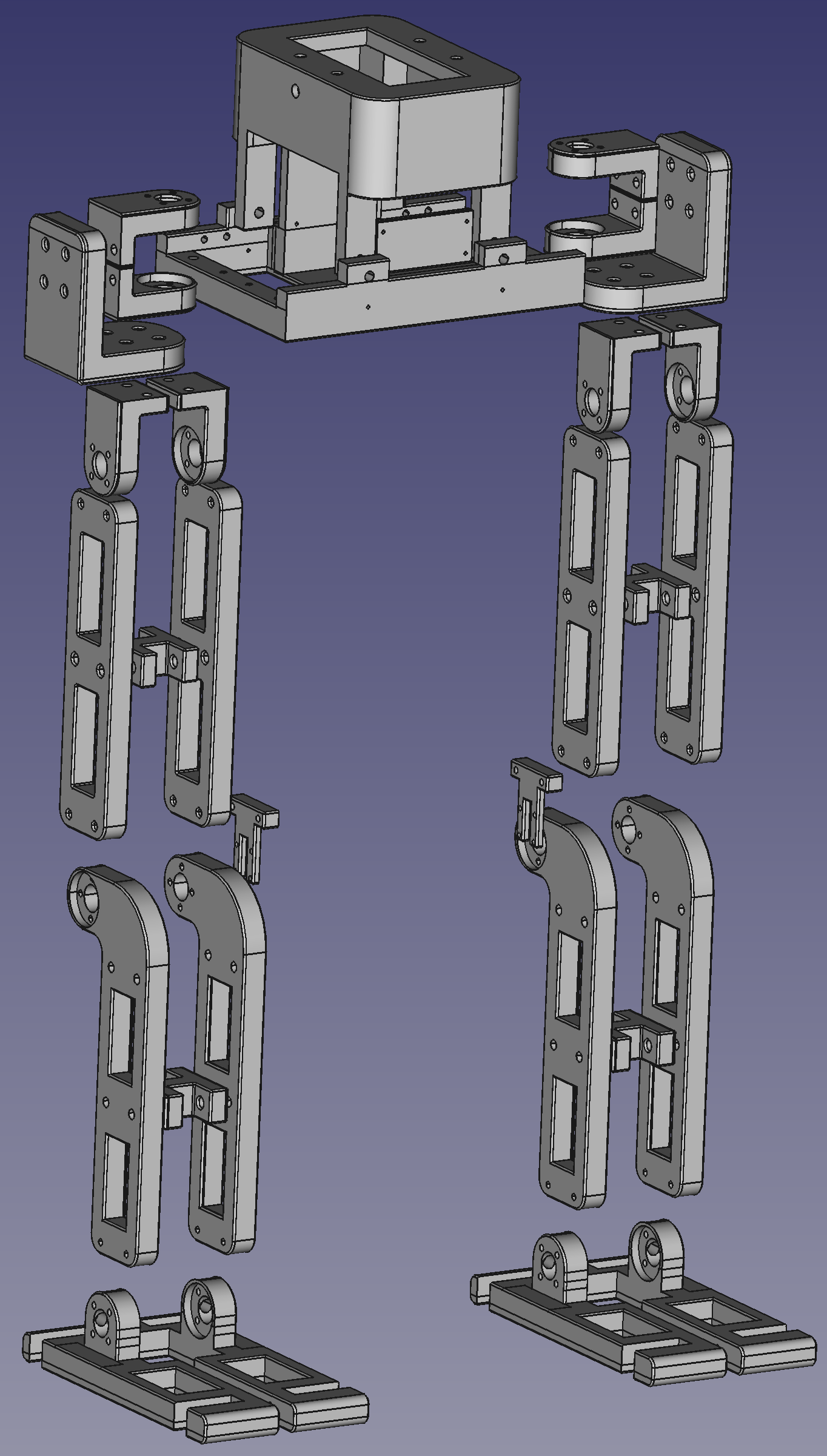
CAD Design

Version 2
Version 3
Simulation
Pybullet was chosen for the simulation for its conveniance and wide support. The "humanoid.urdf" available from the the Pybullet library was rearrangement and upgraded to make it as close as possible to the designed robot (links lengths, type of joints, mass, inertia, friction, etc).
During reinforcement learning training, the simulation generates multiple agents (robots) in parallel (that are automatically regenerated either when falling or after the maximum amount of steps per episode - An episode is basically a sequence of steps that a robot takes during a trajectory). A parallelization of 64 to 256 was used and the batch size was set to 50'000, meaning that after that amount of steps, the PPO algorithm recalculates the new optimal weights of the neural network. Episodes were set to last 300 steps, so trajectories are equivalent to 10 seconds or less at 30Hz.

Parallel training
Results
The first task for the robot was learning to stay standing, which ended up taking about 20'000 episodes for the lower body (about 10 minutes of parallel training on the GPU Nvidia RTX 4090).
Learning to walk takes over a 100'000 episodes and several hours. The "walking" task actually uses the weights learned from the "standing" task, something referred to as "curriculum learning" - increasing the difficulty of tasks over time.
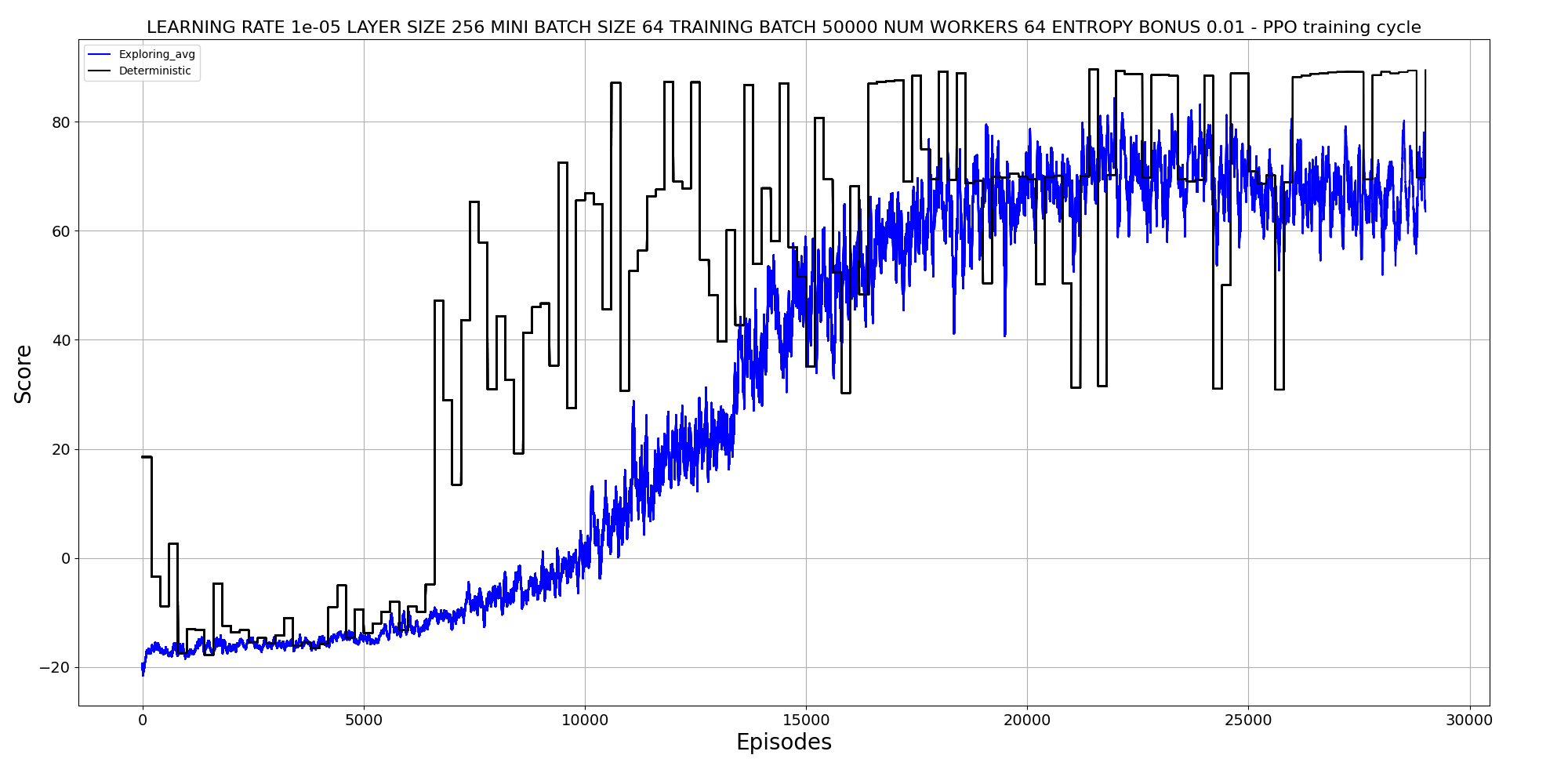
Learning to stay standing - rewards over time
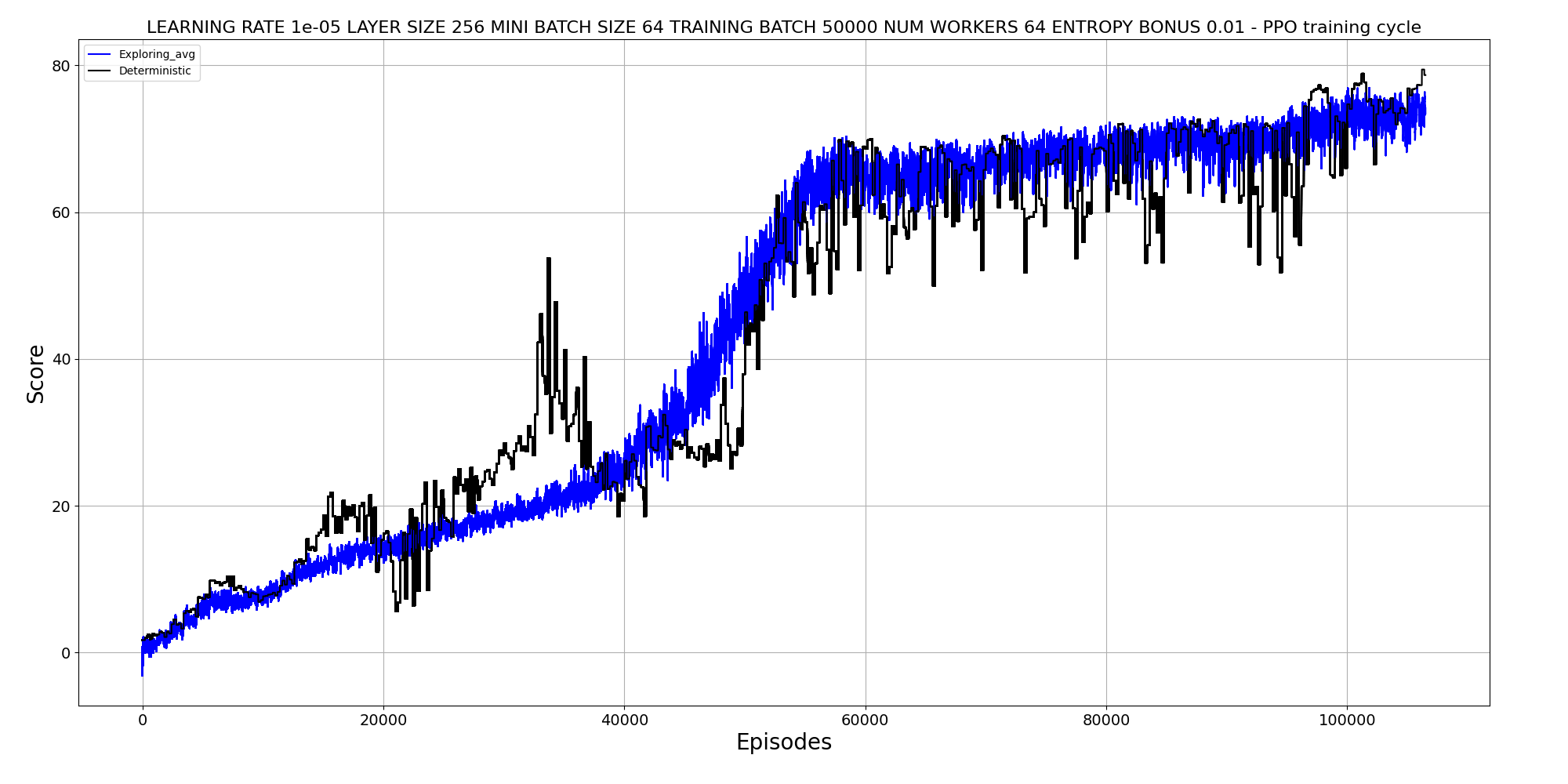
Learning to mimic a squat
This ensures that even if the real robot has different dynamics compared to the simulation, the robot will be ok because it learned to do the tasks "no matter the imprecision of the real world". But still, simulation-to-real transfer remains an extremely hard challenge.
Standing and resisting perturbations
Walking
Walking and resisting perturbations
Pose estimation of a squat
Lower body mimicking the squat
Full body mimicking the squat
Next Steps
The progress so far is promising, with successful implementation of many core functionalities. However, the primary challenge remains: achieving transferability from the simulated environment to the physical robot. Once this is achieved, the upper body will be assembled. Other key challenges coming:
- ⚡ Processing Optimization: Reduce step processing time (currently at about 20ms) - the goal should be 8ms to transition from 30Hz to over 100Hz for smoother control.
- 🔧 Hardware Upgrades: Replace the underpowered actuators (knee and ankles) with motors that can deliver over 20Nm and add current sensors for torque control
- 🏗️ Structural Improvements: Redesign motor joints to minimize play and improve structural stability.
- 🤖 Upper Body and Vision System: Finish the design of the upper body, assemble and integrate 2 cameras, a speaker and a microphone
- 🗺️ Perception and Navigation: Implement navigation algorithm and integrate the vision models for objects recognition.
- 🗣️ Task Understanding: Implement speech-to-text and text-to-task models with LLMs.
- 🔀 Parallelization improvement: Pybullet does not use GPU for simulation, switch to something else like Isaac Gym
- 🧠 Learning Enhancements: Use diffusion models for reward function estimation and update the vision models with state-of-the-art transformers.
Interested in this project?
Annexe I: Electronics schema
Some symbols are missing in the kicad library, so similar ones have been used instead: AS5047D represents the encoder AS5600, TCA9534 represents the multiplexer TCA9748A and PCA9685BS represents the motors driver PCA685. The wires coming from the Raspberry Pi to each motor on the right side are direction signals. The wires coming from the left of the motors are the PWM from the driver.
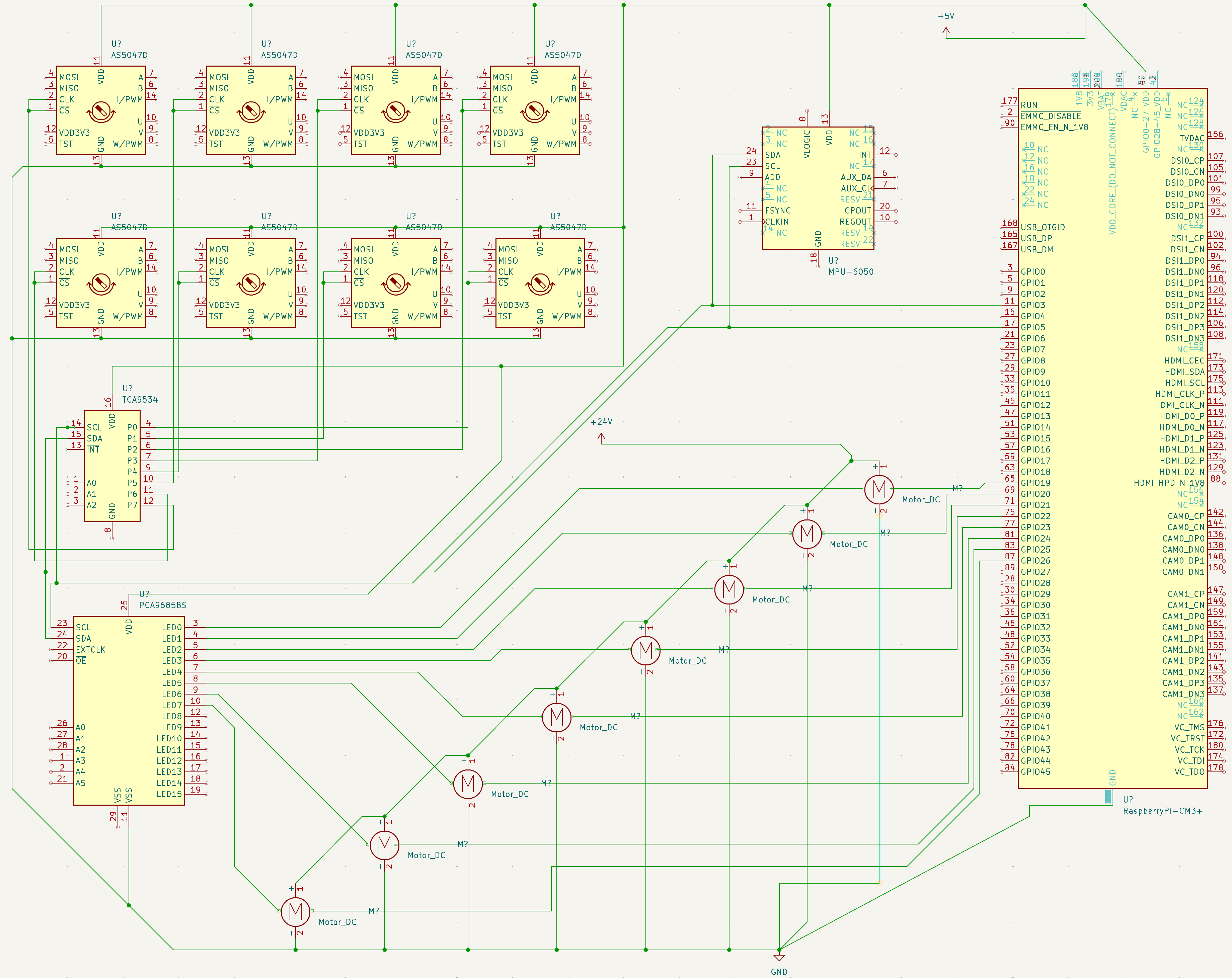
Kicad electronics schema (lower body only - velocity control)
Annexe II: Development Timeline
| Month | Phase | Key Developments |
|---|---|---|
| April 2024 | Foundation and Initial Setup | Built PyBullet simulations, implemented PPO, studied Sim2Real transfer |
| May | Standing and Early Motion | Implemented RL for standing based on torque control, added parallelization, refined reward shaping, started the robot design |
| June | Neural Network Optimization | Implemented DeepMimic, ordered electronic components, created FreeCAD parts, implemented new reward functions (walking, decreasing energy, smoothness) |
| July | Hardware Integration | Cleaned codebase, programmed the Raspberry Pi, conducted velocity & position control experiments, hyperparameter tuning |
| August | Vision and Sensor Improvements | Implemented image recognition and depth estimation, added gyroscope, encoders, multiplexers & IO extenders. |
| September | Structural Improvements | Added domain randomization, developed a standing-up task, printed lower-body components, estimated motor dynamics through experiments. |
| 4-Month Break - working on another project | ||
| February 2025 | Resuming Development | Tested higher velocity & torque, improved DeepMimic implementation, improved robot parts |
Annexe III: Project Cost Breakdown
| Item | Price ($) | Units | Total ($) |
|---|---|---|---|
| PLA Filament - 1Kg | 22 | 2 | 44 |
| Raspberry Pi 5 - 8GB | 88 | 1 | 88 |
| PCA9685 Servo Driver | 3 | 3 | 9 |
| DC Motors 5840-3650 | 24 | 14 | 336 |
| DC Motor 36GP-3650 | 30 | 1 | 30 |
| MPU6050 Gyroscope | 2 | 1 | 2 |
| Rubber Grip Tape - 100cm | 2 | 1 | 2 |
| MicroSD Card - 64GB | 9 | 1 | 9 |
| Small Servo Motor with Encoder | 7 | 20 | 140 |
| DC Buck Converter (12/24V to 5V) | 1 | 1 | 1 |
| Jumper Wires Set | 3 | 2 | 6 |
| Flange Coupling | 1 | 31 | 31 |
| TCA9548A I2C Multiplexer | 1 | 3 | 3 |
| 24V Battery | 33 | 1 | 33 |
| USB Camera (OV3660) | 9 | 2 | 18 |
| Mini USB Microphone | 2 | 1 | 2 |
| AS5600 Magnetic Encoder | 1 | 15 | 15 |
| Speaker Driver Module | 1 | 1 | 1 |
| Screws and Bolts Assortment | 11 | 1 | 11 |
| Large Servo Motors (Neck and Wrist) | 16 | 3 | 48 |
| ADS1115 Analog-to-Digital Converter | 1 | 6 | 6 |
| External 5V Amplifier with Volume Control | 1 | 1 | 1 |
| Bearings for Fingers Pack | 1 | 1 | 1 |
| Bearings for Motors | 1 | 29 | 29 |
| 2mm Shaft for Fingers Pack | 1 | 1 | 1 |
| 1mm Screws for Fingers Pack | 1 | 1 | 1 |
| Silicone | 1 | 1 | 1 |
| Thread for Fingers | 1 | 1 | 1 |
| 1m Jack Audio Extender | 1 | 1 | 1 |
| 0.5m USB Extender | 1 | 3 | 3 |
| Total | 874 |